Senzing Entity Specification
This document defines the Senzing Entity Specification — a detailed guide for mapping source data into Senzing’s entity resolution engine.
The process of mapping is taking a source field name, like CustomerName, and transforming it into a target field name, by applying specific rules, such as renaming, reformatting, or combining fields based on predefined logic or conditions. It’s like creating a bridge where data from one system is reshaped to fit the structure of another system, guided by those rules.
Key terms

Entities, features and attributes
- Entity — A real-world subject, primarily a
PERSONor anORGANIZATION, described by one record. - Feature — A set of related attributes about the entity (e.g.,
NAME,ADDRESS,PHONE). - Attribute — A single field within a feature (e.g.,
NAME_FIRSTandNAME_LASTinNAME;ADDR_LINE1inADDRESS).
Usage types and payload (optional attributes)
- Usage Type — A short label that distinguishes multiple instances of the same feature on one entity (e.g.,
HOMEvsMAILINGaddress,MOBILEvsHOMEphone,PRIMARYvsALIASname). It helps explain “which one it is” when there are several. - Payload Attributes — These are attributes that are not used for matching, but can be helpful in understanding matches or making quick decisions. (e.g.,
STATUS: Active|Inactive,RISK_CATEGORY,INDUSTRY_CODE)
What features to map
Entity resolution works best when you have a name and as many other features as you can find. The more features on each record, the better the entity resolution! Below are feature lists to look for in your sources. Rank indicates typical importance to entity resolution.
The feature names themselves are not mapped with record data; the attributes for the features are mapped. For example, a mapped NAME feature:
{ "NAME_FIRST": "Robert", "NAME_LAST": "Smith", "NAME_MIDDLE": "A" }
| Feature | Description | Importance | Guidance |
|---|---|---|---|
| Registered Feature Attributes | DATA_SOURCE (REQUIRED) and RECORD_ID (Strongly Recommended) |
Very High | These attributes tie records in Senzing back to your source system. |
| RECORD_TYPE | (e.g., PERSON, ORGANIZATION) |
High | Include when known to prevent cross‑type resolution; omit if unknown. Use standardized kinds (PERSON, ORGANIZATION). Often used to determine icon/shape in graphs. |
| NAME (person) | Personal names | High | Look for: legal name, aliases/AKAs, maiden/former names, nickname/preferred name, transliterations/alternate scripts. Prefer parsed components when available (NAME_FIRST, NAME_MIDDLE, NAME_LAST, NAME_PREFIX, NAME_SUFFIX). |
| NAME (organization) | Organization legal or trade name | High | Look for: legal/registered name, trade/DBA, former names, short/brand names, transliterations/alternate scripts. (NAME_ORG) |
| DOB | Person date of birth | High | Full date preferred; partial values accepted. |
| ADDRESS (person) | Postal/physical address | High | Look for: residential/home, mailing/remittance, previous/old; prefer parsed components when available (ADDR_LINE1, ADDR_LINE2, ADDR_CITY, ADDR_STATE, ADDR_POSTAL_CODE, ADDR_COUNTRY). |
| ADDRESS (organization) | Organization location address | High | Look for: physical/business/registered office, mailing/remittance; prefer parsed components when available (ADDR_LINE1, ADDR_LINE2, ADDR_CITY, ADDR_STATE, ADDR_POSTAL_CODE, ADDR_COUNTRY). |
| PASSPORT | Passport identifier | High | Include issuing country. |
| DRLIC | Driver’s license | High | Include issuing state/province/country. |
| SSN | US Social Security Number | High | Partial values accepted. |
| TAX_ID | Tax identifier | High | Look for: EIN, VAT, TIN/ITIN; include issuing country. |
| NATIONAL_ID (person) | National/person identifier | High | Look for country‑specific IDs; include issuing country. Common examples: SIN (CA), CURP (MX), NINO (UK), NIR/INSEE (FR). |
| NATIONAL_ID (organization) | National/company registration identifier | High | Look for company registry numbers (not tax/VAT); include issuing country. Common examples: Company Number/CRN (UK), SIREN/SIRET (FR), Corporation Number (CA), Folio Mercantil (MX). |
| PHONE | Telephone number | Medium | Look for all phone numbers; distinguish mobile if possible; personal mobile numbers carry additional weight. |
| Email address | Medium | — | |
| Social handles | Social/media handles | Medium | Features include: LINKEDIN, FACEBOOK, TWITTER, SKYPE, ZOOMROOM, INSTAGRAM, WHATSAPP, SIGNAL, TELEGRAM, TANGO, VIBER, WECHAT. |
| DUNS_NUMBER | Company identifier | Medium | — |
| LEI_NUMBER | Legal Entity Identifier | Medium | — |
| NPI_NUMBER | US healthcare provider ID | Medium | — |
| ACCOUNT | Account or card number | Medium | Look for bank or other account numbers that can aid resolution, especially across data sources. |
| OTHER_ID | Other/uncategorized identifier | Medium | For identifier types that can’t be mapped to one of Senzing’s specific identifier features. Use sparingly; if an identifier is used frequently, create a dedicated feature for it. |
| GENDER | Person gender | Low-Medium | — |
| EMPLOYER | Name of a person’s employer | Medium-Low | Can aid resolution on smaller companies; subject to generic thresholds; form of group association. |
| GROUP_ASSOCIATION | Other organization names an entity is associated with | Medium-Low | Can aid resolution on smaller domains, subject to generic thresholds. |
| GROUP_ASSN_ID | Group identifier | Medium-Low | Can aid resolution on smaller domains, subject to generic thresholds. |
| DOD | Person date of death | Medium-Low | When applicable. |
| REGISTRATION_DATE | Organization registration/incorporation date | Medium-Low | Full date preferred; partial values accepted. |
| REGISTRATION_COUNTRY | Organization registration country | Low | — |
| NATIONALITY | Person nationality | Low | — |
| CITIZENSHIP | Person citizenship | Low | — |
| PLACE_OF_BIRTH | Person place of birth | Low | Typically not well controlled. |
| WEBSITE | Organization website/domain | Low | Typically shared across the organization’s hierarchy. |
| REL_ANCHOR | Relationship anchor for a source record | Relationship | Optional (recommended when other records will point here); at most one per record. |
| REL_POINTER | Pointer to another record’s anchor | Relationship | Place on source record; include REL_POINTER_ROLE (e.g., EMPLOYED_BY, PRINCIPAL_OF, OWNER_OF, SPOUSE_OF, SON_OF, FATHER_OF, BRANCH_OF, DIRECT_PARENT, ULTIMATE_PARENT). |
| TRUSTED_ID | Curated control identifier | Control | Forces records together or apart; like a curated ID layered over source IDs. Use cautiously per guidance. |
Payload attributes (optional)
The full details about a record should exist in your source systems. Senzing holds the features needed for entity resolution and acts as a pointer system to where the full details of their record can be found.
Payload attributes are optional because they are not used in matching. However, they can help a human reviewer quickly triage a match and decide whether looking up the full record is warranted.
Here are some examples of useful payload attributes:
STATUS: Active/Inactive helps triage quickly (e.g., ignore inactive duplicates; focus on active customers).CREATE_DATE(orFIRST_SEEN): Helps sort duplicates and spot fraud risk (e.g., a new record with conflicting identifiers vs. an older established one).INDUSTRY_CODE/INDUSTRY: Codes and labels from data providers that describe the business (e.g., NAICS/SIC).JOB_TITLE: Role/title from HR or data providers; can inform risk, especially when matched to a watchlist entry.RISK_CATEGORY/RISK_SCORE: Watchlist-derived codes/scores that explain the type and severity of risk.
Performance note:
- Payload increases storage and I/O. Include only when it materially improves downstream understanding. On very large systems, evaluate impact before enabling broadly.
- If you do decide to include them, keep them minimal and only include what helps a human understand matches or an algorithm to triage them.
- You may decide to map a few during a proof of concept while you are analyzing matches and then remove them when you go to production.
Registered feature attributes
Attributes for the record key
These attributes tie records in Senzing back to your source system. Place them at the root of each JSON record.
| Attribute | Required | Example | Guidance |
|---|---|---|---|
DATA_SOURCE |
Required | CUSTOMERS | Short, stable code naming the source (e.g., CUSTOMERS). If you have multiple similar sources, use distinct codes (e.g., BANKING_CUSTOMERS, MORTGAGE_CUSTOMERS). Prefer uppercase, no spaces. Used for retrieval and reporting — keep it consistent. |
RECORD_ID |
Strongly Recommended | 1001 | Must be unique within DATA_SOURCE; used to add/replace records. If the source lacks a primary key, construct a deterministic ID (e.g., hash of normalized identifying attributes). If omitted, Senzing generates a hash of features, making updates impractical. Do not duplicate RECORD_ID as a feature — retrieval uses DATA_SOURCE + RECORD_ID. |
Example
{
"DATA_SOURCE": "CUSTOMERS",
"RECORD_ID": "1001"
}
Feature: RECORD_TYPE
Importance: High
| Attribute | Required | Example | Guidance |
|---|---|---|---|
RECORD_TYPE |
Recommended | PERSON | Prevents records of different types from resolving. Include when known to prevent cross‑type resolution; leave blank if unknown. Use standardized kinds (PERSON, ORGANIZATION). Often used to pick the icon/shape in graphs. |
Example
{ "RECORD_TYPE": "PERSON" }
Tips for adding RECORD_TYPEs
- If you choose to add
RECORD_TYPE, pick values that make sense for visualization too (e.g., a value that can map to a graph icon/shape). - Avoid role labels as
RECORD_TYPE(EMPLOYEE,VENDOR,CUSTOMER). Use intrinsic types (PERSON,ORGANIZATION) to preserve cross‑type resolution. - Many watchlists have standardized on values such as
VESSELandAIRCRAFT. You do not need to register these in Senzing to use them asRECORD_TYPE. - If you add such types, also include their appropriate identifiers as
FEATURESso matching remains effective (e.g.,IMO_NUMBER,CALL_SIGNfor vessels;AIRCRAFT_TAIL_NUMBERfor aircraft).
Name
Feature: NAME
Importance: High
| Attribute | Example | Guidance |
|---|---|---|
NAME_TYPE |
PRIMARY | Optional; include when the source provides it. Common values: PRIMARY, AKA (persons), DBA (organizations). |
NAME_FIRST |
Robert | Person given name. |
NAME_LAST |
Smith | Person surname. |
NAME_MIDDLE |
A | Person middle name/initial (optional). |
NAME_PREFIX |
Dr | Person title/prefix (optional). |
NAME_SUFFIX |
Jr | Person suffix (optional). |
NAME_ORG |
Acme Tire Inc. | Organization name. |
NAME_FULL |
Robert J Smith, Trust | Single-field name when type (person vs org) is unknown or only a full name is provided. |
Rules
- Prefer parsed person names (
NAME_FIRST/NAME_LAST/…) when available; useNAME_ORGfor organizations; useNAME_FULLonly when the type is unknown or only a single field exists. - Keep each
NAMEfeature object internally consistent: do not mixNAME_FULLwith parsed name fields in the same object; do not mixNAME_ORGwith parsed person fields in the same object. - Use
NAME_TYPEonly when provided by the source (e.g.,PRIMARY,AKA,DBA). - When multiple names exist,
NAME_TYPE=PRIMARYis special: it determines the best display name for the resolved entity (preferPRIMARYoverAKA).
Examples
- ✅ Person (parsed)
{
"FEATURES": [
{ "NAME_FIRST": "Robert", "NAME_LAST": "Smith", "NAME_MIDDLE": "A" }
]
}
- ✅ Organization
{
"FEATURES": [{ "NAME_ORG": "Acme Tire Inc.", "NAME_TYPE": "PRIMARY" }]
}
- ✅ Unknown type
{
"FEATURES": [{ "NAME_FULL": "Robert J Smith, Trust" }]
}
- ❌ Incorrect (split across multiple
NAMEobjects)
{
"FEATURES": [{ "NAME_LAST": "Smith" }, { "NAME_FIRST": "Robert" }]
}
- ❌ Incorrect (mixing
NAME_ORGwith parsed person fields)
{
"FEATURES": [{ "NAME_ORG": "Acme Tire Inc.", "NAME_FIRST": "Robert" }]
}
Contact methods
Feature: ADDRESS
Importance: High
| Attribute | Example | Guidance |
|---|---|---|
ADDR_TYPE |
HOME | Optional; include when provided by the source. Common values: HOME, MAILING (persons); BUSINESS (organizations). |
ADDR_LINE1 |
111 First St | First address line (street, number). |
ADDR_LINE2 |
Suite 101 | Second address line (apt/suite). |
ADDR_LINE3 |
Third address line (optional). | |
ADDR_LINE4 |
Fourth address line (optional). | |
ADDR_LINE5 |
Fifth address line (optional). | |
ADDR_LINE6 |
Sixth address line (optional). | |
ADDR_CITY |
Las Vegas | City/locality. |
ADDR_STATE |
NV | State/province/region code. |
ADDR_POSTAL_CODE |
89111 | Postal/ZIP code. |
ADDR_COUNTRY |
US | Country code. |
ADDR_FULL |
3 Underhill Way, Las Vegas, NV 89101, US | Single-field address when parsed components are unavailable. |
Rules
- Prefer parsed address fields when available (
ADDR_LINE1..ADDR_LINE6,ADDR_CITY,ADDR_STATE,ADDR_POSTAL_CODE,ADDR_COUNTRY). - Use
ADDR_FULLonly when parsed components are unavailable. - Do not mix
ADDR_FULLwith parsed address fields in the same object. - For organizations, assign
ADDR_TYPE=BUSINESSto at least one address when known (adds weight to the physical location).
Examples
- ✅ Parsed address
{
"FEATURES": [
{
"ADDR_TYPE": "HOME",
"ADDR_LINE1": "111 First St",
"ADDR_CITY": "Las Vegas",
"ADDR_STATE": "NV",
"ADDR_POSTAL_CODE": "89111"
}
]
}
- ✅ Single-field address
{
"FEATURES": [
{
"ADDR_TYPE": "MAILING",
"ADDR_FULL": "3 Underhill Way, Las Vegas, NV 89101, US"
}
]
}
- ❌ Incorrect (mixing
ADDR_FULLwith parsed fields)
{
"FEATURES": [
{
"ADDR_FULL": "123 Main St, Las Vegas, NV 89132",
"ADDR_CITY": "Las Vegas"
}
]
}
Feature: PHONE
Importance: Medium
| Attribute | Example | Guidance |
|---|---|---|
PHONE_TYPE |
MOBILE | Optional; include when provided by the source. Common values: MOBILE, HOME, WORK, FAX. MOBILE carries extra weight. |
PHONE_NUMBER |
702-555-1212 | Telephone number. |
Rules
- Include
PHONE_TYPEonly when the source provides it (MOBILEcarries extra weight). - One
PHONEobject per number; represent multiple numbers as multiplePHONEobjects. - Do not put a list of numbers inside a single
PHONEobject. - When a source uses clear prefixes (e.g., HOME_PHONE), you may derive
PHONE_TYPEfrom the prefix.
Example
{
"FEATURES": [
{ "PHONE_TYPE": "MOBILE", "PHONE_NUMBER": "702-555-1212" },
{ "PHONE_NUMBER": "702-555-3434" }
]
}
Feature: EMAIL
Importance: Medium
| Attribute | Example | Guidance |
|---|---|---|
EMAIL_ADDRESS |
[email protected] | Email address. |
Example
{
"FEATURES": [{ "EMAIL_ADDRESS": "[email protected]" }]
}
Physical and other characteristics
Feature: GENDER
Importance: Low-Medium
| Attribute | Example | Guidance |
|---|---|---|
GENDER |
M | Gender code or label from the source. For matching, only M, F, Male, and Female are considered; other values are ignored to avoid denials (e.g., M vs UNK). |
Example
{
"FEATURES": [{ "GENDER": "F" }]
}
Feature: DOB (date of birth)
Importance: High
| Attribute | Example | Guidance |
|---|---|---|
DATE_OF_BIRTH |
1980-05-14 | Complete dates preferred; partial dates accepted when only partial is available (e.g., YYYY-MM or MM-DD). |
Example
{
"FEATURES": [{ "DATE_OF_BIRTH": "1980-05-14" }]
}
Feature: DOD (date of death)
Importance: Low-Medium
| Attribute | Example | Guidance |
|---|---|---|
DATE_OF_DEATH |
2010-05-14 | Complete dates preferred; partial dates accepted when only partial is available (e.g., YYYY-MM or MM-DD). |
Example
{
"FEATURES": [{ "DATE_OF_DEATH": "2010-05-14" }]
}
Feature: NATIONALITY
Importance: Low
| Attribute | Example | Guidance |
|---|---|---|
NATIONALITY |
US | Country of nationality (code or label) as provided by the source. |
Example
{
"FEATURES": [{ "NATIONALITY": "US" }]
}
Feature: CITIZENSHIP
Importance: Low
| Attribute | Example | Guidance |
|---|---|---|
CITIZENSHIP |
US | Country of citizenship (code or label) as provided by the source. |
Example
{
"FEATURES": [{ "CITIZENSHIP": "US" }]
}
Feature: POB (place of birth)
Importance: Low
| Attribute | Example | Guidance |
|---|---|---|
PLACE_OF_BIRTH |
Chicago | Place of birth; may be a city/region or a country code/label as provided by the source. |
Example
{
"FEATURES": [{ "PLACE_OF_BIRTH": "Chicago, IL" }]
}
Feature: REGISTRATION_DATE (organizations)
Importance: Low-Medium
| Attribute | Example | Guidance |
|---|---|---|
REGISTRATION_DATE |
2010-05-14 | Organization registration/incorporation date. Complete dates preferred; partial dates accepted when only partial is available (e.g., YYYY-MM or MM-DD). |
Example
{
"FEATURES": [{ "REGISTRATION_DATE": "2010-05-14" }]
}
Feature: REGISTRATION_COUNTRY (organizations)
Importance: Low
| Attribute | Example | Guidance |
|---|---|---|
REGISTRATION_COUNTRY |
US | Country of registration (code or label) as provided by the source. |
Example
{
"FEATURES": [{ "REGISTRATION_COUNTRY": "US" }]
}
Identifiers
Feature: PASSPORT
Importance: High
| Attribute | Example | Guidance |
|---|---|---|
PASSPORT_NUMBER |
123456789 | Passport number. |
PASSPORT_COUNTRY |
US | Issuing country. Strongly recommended. |
Example
{
"FEATURES": [{ "PASSPORT_NUMBER": "123456789", "PASSPORT_COUNTRY": "US" }]
}
Feature: DRLIC (driver’s license)
Importance: High
| Attribute | Example | Guidance |
|---|---|---|
DRIVERS_LICENSE_NUMBER |
112233 | Driver’s license number. |
DRIVERS_LICENSE_STATE |
NV | Issuing state/province/country. Strongly recommended. |
Example
{
"FEATURES": [
{ "DRIVERS_LICENSE_NUMBER": "112233", "DRIVERS_LICENSE_STATE": "NV" }
]
}
Feature: SSN (US social security number)
Importance: High
| Attribute | Example | Guidance |
|---|---|---|
SSN_NUMBER |
123-12-1234 | US Social Security Number; partial accepted. |
Example
{
"FEATURES": [{ "SSN_NUMBER": "123-12-1234" }]
}
Feature: NATIONAL_ID
Importance: High
| Attribute | Example | Guidance |
|---|---|---|
NATIONAL_ID_TYPE |
CEDULA | Use the type label from the source; standardize across sources. |
NATIONAL_ID_NUMBER |
123121234 | National identifier value. |
NATIONAL_ID_COUNTRY |
FR | Issuing country. Strongly recommended. |
Rules
- If the source type cannot be standardized and
NATIONAL_ID_COUNTRYis present, leaveNATIONAL_ID_TYPEblank.
Good/Bad
- ✅ Good
{
"FEATURES": [
{
"NATIONAL_ID_TYPE": "SIREN",
"NATIONAL_ID_NUMBER": "552081317",
"NATIONAL_ID_COUNTRY": "FR"
}
]
}
- ❌ Bad (SSN mapped as
NATIONAL_ID)
{
"FEATURES": [
{ "NATIONAL_ID_TYPE": "SSN", "NATIONAL_ID_NUMBER": "123-12-1234" }
]
}
Feature: TAX_ID
Importance: High
| Attribute | Example | Guidance |
|---|---|---|
TAX_ID_TYPE |
EIN | Use the type label from the source; standardize across sources. |
TAX_ID_NUMBER |
12-3456789 | Tax identification number. |
TAX_ID_COUNTRY |
US | Issuing country. Strongly recommended. |
Rules
- If the source type cannot be standardized and
TAX_ID_COUNTRYis present, leaveTAX_ID_TYPEblank.
Good/Bad
- ✅ Good
{
"FEATURES": [
{
"TAX_ID_TYPE": "EIN",
"TAX_ID_NUMBER": "12-3456789",
"TAX_ID_COUNTRY": "US"
}
]
}
- ❌ Bad (EIN as
NATIONAL_ID)
{
"FEATURES": [
{
"NATIONAL_ID_TYPE": "EIN",
"NATIONAL_ID_NUMBER": "12-3456789",
"NATIONAL_ID_COUNTRY": "US"
}
]
}
Feature: OTHER_ID
Importance: Medium
| Attribute | Example | Guidance |
|---|---|---|
OTHER_ID_TYPE |
ISIN | Standardized source type strongly recommended as not always issued by a country |
OTHER_ID_NUMBER |
123121234 | Identification number. |
OTHER_ID_COUNTRY |
MX | Optional as country often not known or issued by an organization |
Use OTHER_ID sparingly. Prefer adding a specific feature for frequently used non‑country identifiers so matching behavior can be adjusted.
Do not use OTHER_ID for values that are not unique to an entity within the domain.
Good/Bad
- ✅ Good
{
"FEATURES": [{ "OTHER_ID_TYPE": "ISIN", "OTHER_ID_NUMBER": "123121234" }]
}
- ❌ Bad (Category as an Identifier)
{
"FEATURES": [
{ "OTHER_ID_TYPE": "SDN Type", "OTHER_ID_NUMBER": "Sanctions List" }
]
}
- ❌ Bad (Date as an Identifier)
{
"FEATURES": [
{ "OTHER_ID_TYPE": "Certificate date", "OTHER_ID_NUMBER": "12/11/1980" }
]
}
Feature: ACCOUNT
Importance: Medium
| Attribute | Example | Guidance |
|---|---|---|
ACCOUNT_NUMBER |
1234-1234-1234-1234 | Account number (e.g., bank, card). |
ACCOUNT_DOMAIN |
VISA | Domain/system for the account number. |
Example
{
"FEATURES": [
{ "ACCOUNT_NUMBER": "1234-1234-1234-1234", "ACCOUNT_DOMAIN": "VISA" }
]
}
Feature: DUNS_NUMBER
Importance: Medium
| Attribute | Example | Guidance |
|---|---|---|
DUNS_NUMBER |
123123 | Dun & Bradstreet company identifier. |
Example
{
"FEATURES": [{ "DUNS_NUMBER": "123123" }]
}
Feature: NPI_NUMBER
Importance: Medium
| Attribute | Example | Guidance |
|---|---|---|
NPI_NUMBER |
123123 | US healthcare provider identifier. |
Example
{
"FEATURES": [{ "NPI_NUMBER": "123123" }]
}
Feature: LEI_NUMBER
Importance: Medium
| Attribute | Example | Guidance |
|---|---|---|
LEI_NUMBER |
123123 | Legal Entity Identifier. |
Example
{
"FEATURES": [{ "LEI_NUMBER": "123123" }]
}
Website and social media attributes
Feature: WEBSITE
Importance: Low
| Attribute | Example | Guidance |
|---|---|---|
WEBSITE_ADDRESS |
somecompany.com | Website or domain; typically for organizations. |
Example
{
"FEATURES": [{ "WEBSITE_ADDRESS": "acmetire.com" }]
}
Features for social media handles
Importance: Medium
Social handle features use the feature name as the attribute name.
| Feature/Attribute | Example | Guidance |
|---|---|---|
LINKEDIN |
in/jane-doe | Canonical handle/ID; no URL; no leading @. |
FACEBOOK |
brand.page | Canonical handle/ID; no URL; no leading @. |
TWITTER |
john_doe | Canonical handle/ID; no URL; no leading @. |
SKYPE |
handle | Canonical handle/ID; no URL. |
ZOOMROOM |
room-id | Canonical handle/ID; no URL. |
INSTAGRAM |
jane.doe | Canonical handle/ID; no URL; no leading @. |
WHATSAPP |
+14155551234 | Canonical handle/ID; also map to PHONE. |
SIGNAL |
+14155551234 | Canonical handle/ID; also map to PHONE. |
TELEGRAM |
acme_support | Canonical handle/ID; strip t.me/. |
TANGO |
handle | Canonical handle/ID; no URL. |
VIBER |
+14155551234 | Canonical handle/ID; also map to PHONE. |
WECHAT |
handle | Canonical handle/ID; no URL. |
Rules
-
Normalize values: store the canonical handle/ID, not a full URL. Strip
http(s)://,www., trailing slashes, query params, and a leading@. -
One handle per object: add one
FEATURESobject per platform handle; do not concatenate multiple handles. -
Prefer handle/ID over URL: if only a profile URL is provided, extract the handle/ID.
-
Don’t use content links: skip post/status URLs; only capture profile-level handles/IDs.
-
Case handling: store handles lowercased for case‑insensitive platforms; preserve exact case if a platform is case‑sensitive.
-
Phone‑based apps: when a handle is a phone number (e.g., WhatsApp, Signal, Viber), also map the number to
PHONEin addition to the app‑specific feature. -
Persons vs organizations: map personal handles on person records and brand handles on organization records when known; avoid crossing them.
-
Stability: handles can change; use alongside stronger identifiers (email, phone, gov IDs).
-
Platform specifics
TWITTER(X): letters, numbers, underscores; length 1–15; case‑insensitive.INSTAGRAM: letters, numbers, periods, underscores; length 1–30; case‑insensitive.TELEGRAM: letters, numbers, underscores; 5–32; case‑insensitive; stript.me/.LINKEDIN: prefer the public slug (e.g.,in/jane-doeorcompany/acme); if only a URL is provided, extract the slug.
Example
{
"FEATURES": [{ "LINKEDIN": "in/john-smith" }, { "TWITTER": "janedoe" }]
}
Group associations
See Mapping Group Associations (small groups only) for guidance and examples.
Feature: EMPLOYER
Importance: Low-Medium
| Attribute | Example | Guidance |
|---|---|---|
EMPLOYER |
ABC Company | This is the name of the organization the person is employed by. |
Rules
- When the source provides explicit employment relationships between person and organization records, prefer
REL_POINTER/REL_ANCHORto model the relationship;EMPLOYERcan still be included for resolution.
Example
{
"FEATURES": [{ "EMPLOYER": "ABC Company" }]
}
Feature: GROUP_ASSOCIATION
Importance: Low-Medium
| Attribute | Example | Guidance |
|---|---|---|
GROUP_ASSOCIATION_TYPE |
OWNER_EXEC | Specific group/role within the organization; use precise categories (e.g., OWNER_EXEC, BOARD_MEMBER) to improve resolution. |
GROUP_ASSOCIATION_ORG_NAME |
Group name | Name of the associated organization; use the official or standardized name. |
Rules
- Provide
GROUP_ASSOCIATION_TYPEto keep the group specific. Specific roles/groups (e.g., owners/executives of a company) are much smaller than the general population and therefore more discriminative. - Only use when the group is small and specific; primarily useful in sparse data contexts.
- Do not set
GROUP_ASSOCIATIONfor broad populations (e.g., political parties, religions, national populations, country/state residents, mega social networks). - Provide a precise
GROUP_ASSOCIATION_TYPEand a specificGROUP_ASSOCIATION_ORG_NAME. - Example of discriminative power: the combination of a name with a small group (e.g., “George Washington” + “US President”) is far rarer than the name alone.
Example
{
"FEATURES": [
{
"GROUP_ASSOCIATION_TYPE": "OWNER_EXEC",
"GROUP_ASSOCIATION_ORG_NAME": "ABC Company"
}
]
}
Feature: GROUP_ASSN_ID
Importance: Low-Medium
| Attribute | Example | Guidance |
|---|---|---|
GROUP_ASSN_ID_TYPE |
COMPANY_ID | The type of group identifier an entity is associated with. |
GROUP_ASSN_ID_NUMBER |
12345 | The identifier the entity is associated with. If the group has a registered identifier, place it here. |
Rules
- Use when the group/organization has a registered identifier (e.g., DUNS). Include both type and number when available.
Example
{
"FEATURES": [
{ "GROUP_ASSN_ID_TYPE": "COMPANY_ID", "GROUP_ASSN_ID_NUMBER": "12345" }
]
}
Trusted ID
Feature: TRUSTED_ID
Category: Control
Two records with the same TRUSTED_ID type and number will absolutely force records together even if all their other features are different. Conversely, two records with a different TRUSTED_ID number of the same type will be forced apart even if all their other features are the same.
This feature can be used by data stewards to manually force records together or apart. It can also be used for a source system identifier that is so trusted you want it to never be overruled by Senzing.
| Attribute | Example | Guidance |
|---|---|---|
TRUSTED_ID_TYPE |
STEWARD | Short code for the identifier domain/system (e.g., STEWARD, MASTER_ID). |
TRUSTED_ID_NUMBER |
1234-12345 | The identifier value shared by records that must resolve together. |
Example
{
"FEATURES": [
{ "TRUSTED_ID_TYPE": "STEWARD", "TRUSTED_ID_NUMBER": "1234-12345" }
]
}
Disclosed relationships
See Disclosed Relationship Mapping Guidance above for model, direction, cardinality, and field‑population patterns.
Feature: REL_ANCHOR
Category: Relationship
| Attribute | Example | Guidance |
|---|---|---|
REL_ANCHOR_DOMAIN |
CUSTOMERS | This code helps keep the REL_ANCHOR_KEY unique. This is a code (without dashes) for the data source or source field that is contributing the relationship. |
REL_ANCHOR_KEY |
1001 | This key should be a unique value for the record within the REL_ANCHOR_DOMAIN. You can just use the current record’s RECORD_ID here. |
Rules
- Include at most one
REL_ANCHORper record, only when other records will point to it. REL_ANCHORidentifies the target record for relationships usingREL_ANCHOR_DOMAINandREL_ANCHOR_KEY.- Do not mix
REL_ANCHORandREL_POINTERattributes in the same feature object (separate objects inFEATURESare fine). - Use a domain code without dashes to avoid confusion in downstream match key parsing.
Examples
{
"FEATURES": [
{ "REL_ANCHOR_DOMAIN": "CUSTOMERS", "REL_ANCHOR_KEY": "ACME-1001" }
]
}
- ❌ Incorrect (multiple
REL_ANCHORobjects — only one allowed per record)
{
"FEATURES": [
{ "REL_ANCHOR_DOMAIN": "CUSTOMERS", "REL_ANCHOR_KEY": "ACME-1001" },
{ "REL_ANCHOR_DOMAIN": "CUSTOMERS", "REL_ANCHOR_KEY": "ACME-2002" }
]
}
Feature: REL_POINTER
Category: Relationship
| Attribute | Example | Guidance |
|---|---|---|
REL_POINTER_DOMAIN |
CUSTOMERS | See REL_ANCHOR_DOMAIN above. |
REL_POINTER_KEY |
1001 | See REL_ANCHOR_KEY above. |
REL_POINTER_ROLE |
SPOUSE | This is the role the pointer record has to the anchor record. Such as SPOUSE_OF, SON_OF, FATHER_OF, EMPLOYED_BY, PRINCIPAL_OF, OWNER_OF, BRANCH_OF, DIRECT_PARENT, ULTIMATE_PARENT. Standardize these role codes for display and filtering. |
Rules
- Place
REL_POINTERon the source record for each disclosed relationship to a target record. - Provide
REL_POINTER_DOMAINandREL_POINTER_KEYto point to the target’sREL_ANCHOR; include a clearREL_POINTER_ROLE. - Represent multiple relationships by adding multiple
REL_POINTERobjects inFEATURES(one per relationship). - Do not mix
REL_POINTERandREL_ANCHORattributes in the same feature object.
Examples
{
"FEATURES": [
{
"REL_POINTER_DOMAIN": "CUSTOMERS",
"REL_POINTER_KEY": "ACME-1001",
"REL_POINTER_ROLE": "EMPLOYED_BY"
}
]
}
- ❌ Incorrect (mixing
REL_ANCHORandREL_POINTERattributes in the same object)
{
"FEATURES": [
{
"REL_POINTER_DOMAIN": "CUSTOMERS",
"REL_POINTER_KEY": "ACME-1001",
"REL_POINTER_ROLE": "EMPLOYED_BY",
"REL_ANCHOR_DOMAIN": "CUSTOMERS",
"REL_ANCHOR_KEY": "ACME-1001"
}
]
}
Recommended JSON schema
In prior versions we allowed a flat JSON structure with a separate sub-list for each feature that had multiple values. While we still support that, we now recommend the following JSON schema that has just one list for all features. It is much cleaner, and if you standardize on it, you can write a single parser to extract values for downstream processes if needed.
Example (person)
{
"DATA_SOURCE": "CUSTOMERS",
"RECORD_ID": "1001",
"FEATURES": [
{
"RECORD_TYPE": "PERSON"
},
{
"NAME_TYPE": "PRIMARY",
"NAME_LAST": "Smith",
"NAME_FIRST": "Robert"
},
{
"NAME_TYPE": "NICKNAME",
"NAME_FULL": "Bobby Smith"
},
{
"DATE_OF_BIRTH": "1978-12-11"
},
{
"ADDR_TYPE": "HOME",
"ADDR_LINE1": "123 Main Street",
"ADDR_CITY": "Las Vegas",
"ADDR_STATE": "NV",
"ADDR_POSTAL_CODE": "89132"
},
{
"ADDR_TYPE": "MAILING",
"ADDR_FULL": "PO Box 19675, Las Vegas, NV 89111"
},
{
"PHONE_TYPE": "HOME",
"PHONE_NUMBER": "702-919-3211"
},
{
"PHONE_TYPE": "MOBILE",
"PHONE_NUMBER": "702-919-1300"
},
{
"DRIVERS_LICENSE_NUMBER": "112233",
"DRIVERS_LICENSE_STATE": "NV"
},
{
"EMAIL_ADDRESS": "[email protected]"
},
{
"REL_ANCHOR_DOMAIN": "CUSTOMERS",
"REL_ANCHOR_KEY": "1001"
},
{
"REL_POINTER_DOMAIN": "CUSTOMERS",
"REL_POINTER_KEY": "ORG1001",
"REL_POINTER_ROLE": "EMPLOYED_BY"
}
],
"CREATE_DATE": "2020-06-15",
"STATUS": "Active"
}
Example (organization)
{
"DATA_SOURCE": "CUSTOMERS",
"RECORD_ID": "ORG1001",
"FEATURES": [
{
"RECORD_TYPE": "ORGANIZATION"
},
{
"NAME_ORG": "Acme Corporation"
},
{
"ADDR_TYPE": "BUSINESS",
"ADDR_FULL": "500 Industrial Way, Austin, TX 78701, US"
},
{
"PHONE_NUMBER": "+1-512-555-2000"
},
{
"EMAIL_ADDRESS": "[email protected]"
},
{
"LEI_NUMBER": "5493001KJTIIGC8Y1R12"
},
{
"TAX_ID_TYPE": "EIN",
"TAX_ID_NUMBER": "12-3456789",
"TAX_ID_COUNTRY": "US"
},
{
"WEBSITE_ADDRESS": "https://www.acme.example"
},
{
"REL_ANCHOR_DOMAIN": "CUSTOMERS",
"REL_ANCHOR_KEY": "ORG1001"
}
],
"NAICS_CODE": "541511",
"COMPANY_TYPE": "Corporation"
}
Schema Validation Rules
- Root keys
DATA_SOURCE(required, string): short, stable code naming the source system.RECORD_ID(recommended, string): unique within theDATA_SOURCE; used for add/replace.FEATURES(required, array): the only array allowed at root.- Contains only feature objects. Each object represents one instance of a feature’s attributes
- All attributes in a feature object must belong to the same feature
- Optional root level attributes (Payload Attributes)
- Must not be a registered feature attribute
- Must be a scalar object (string, number, boolean), Not an array or nested object
- Only registered feature attributes may appear inside feature objects. See “Registered Feature Attributes” below for the complete list and guidance.
Note: If exporting Senzing JSON records to a file its best to flatten them to create an easy to consume JSONL file.
Source schema types
Sources vary — CSV/TSV and relational tables, JSON/JSONL, XML, Parquet, and graph exports.
Unified terms (applies to all sources)
- Master entity: the master person or organization record (a master table row, a graph node, or a top‑level JSON/XML object). One master → one Senzing entity document.
- Identifying attributes: the attributes that identify/describe the entity (names, addresses, phones, emails, identifiers, websites, etc.). These may appear on the master itself or inside child lists/structures.
- Child lists: one‑to‑many data linked to the master. Depending on source, these appear as separate tables, JSON arrays under the master object, repeated XML elements, Parquet list
columns, or graph attribute nodes. Usually each child record represents one (name, address, phone, identifier, etc.) and contains a type such as alias or dba for a name, home, mailing etc for an address, drivers license, passport, tax_id, etc for an identifier. - Disclosed relationships: links between source records (masters) (person↔org, person↔person, org↔org). Depending on source, these appear as link/bridge tables, foreign keys to other master IDs, JSON pointers, XML references, Parquet join keys, or graph edges.
Format notes (how to spot masters, children, and disclosed relationships)
- CSV/TSV/Relational: master tables for persons/organizations; child tables for names, addresses, phones, identifiers; link tables for relationships. Join on primary/foreign keys; each child row → one feature object.
- JSON/JSONL: master object per entity; child lists are arrays on the master (e.g., names, addresses, phones, ids). Flatten each array element into a separate feature object. Nested objects representing a single value map to a single feature; arrays map to multiple features.
- XML: master element per entity; child lists are repeated child elements; attributes may be XML attributes or elements. Treat repeated elements like JSON arrays: one repeated element → one feature object. Extract scalar values only inside a feature.
- Parquet: when normalized across files, treat like relational; when a single file contains list/struct columns on the master row, treat list
as child lists (one struct → one feature) and struct as a single feature’s values. Join across Parquet datasets on keys where needed. - Graph: nodes representing persons or organizations are master entities; edges from a master to attribute nodes (e.g., address, phone, email, identifiers) represent features; edges between master nodes represent disclosed relationships.
How to map them
- Master entity: each person/org row, node, or top‑level object → one Senzing record; include
RECORD_TYPE(PERSON/ORGANIZATION) when known. - Features: collect identifying attributes from the master and child lists/structures (tables, arrays/repeated elements, list
, property nodes) and group them into features — NAME_*,ADDR_*,PHONE_*,PASSPORT_*, etc. - Disclosed relationships: map links/edges/foreign keys between source records (masters) using
REL_*features. - Output: emit one JSON record per master entity with all
FEATURES(attributes and disclosed relationships) included. - For records that reference entities without unique keys (e.g., sender and receiver on transactions), extract identifying attributes and compute a deterministic
RECORD_IDas a hash of normalized values. Stamp this ID on the source record before mapping to Senzing, and track these IDs on the source side as well. - For records that have features that clearly do not belong to the primary entity (e.g., employer name and address on a contact list, reference name and phone number on a job application), consider creating a second entity related to the primary entity.
- Use a stable normalization recipe (fixed fields and order; trim/collapse whitespace; case‑fold; normalize punctuation/diacritics) before hashing.
General mapping guidance
The following sections cover how Senzing treats record updates versus replacements, usage types, and identifier mapping.
Important: Decisions in this section affect matching behavior and whether records break or reinforce matches. Coordinate changes carefully and validate with sample runs.
- Updating vs Replacing determines which features are present at match time (no hidden history in Senzing).
- Usage types with special meaning (
PRIMARY/BUSINESS/MOBILE) influence display/weighting. - Identifier choices (specific vs
NATIONAL_ID/TAX_ID/OTHER_ID) control break/no‑break behavior.
Updating vs replacing records
Senzing always replaces records. It keeps governance and interpretation clear, avoids storing stale or unknown history in Senzing, and respects data‑provider and watchlist contracts that often forbid retaining prior values. It is also impossible for Senzing alone to know whether a prior address was corrected vs. a move, or whether a missing phone was removed on purpose.
Guidance
- Present all features you wish to retain (including historical values) in a single JSON record at update time.
- If the source keeps feature history, map that history as additional
FEATURES. - If the source lacks history, you may maintain your own small history table (
DATA_SOURCE,RECORD_ID,FEATUREtype, feature JSON) and merge as needed when producing the new record.
Mapping usage types
Senzing matches across usage types because they are not well standardized and are often mislabeled across systems. Therefore, map usage types primarily for reference. However, three usage types do have special meaning that influences display or weighting.
Guidance
- Only include usage types when the source clearly provides them.
- Special meanings that influence resolution/display:
NAME_TYPE=PRIMARY: Used to choose the best display name when multiple names exist.ADDR_TYPE=BUSINESS(organizations): Adds weight to an organization’s physical location.PHONE_TYPE=MOBILE: Adds weight to personal mobile numbers.
Mapping identifiers
How identifiers arrive
- Direct fields: single columns like
SSN,LICENSE_NO,TIN,EIN,LEI, etc. - Child/type table: rows with
id_type,id_number, and sometimesid_countryor issuer (e.g., codes such asSSN,DRIVERS LICENSE,TIN).
Classification workflow (stop at first match)
-
Specific identifier
SSN→SSN- Passport →
PASSPORT+PASSPORT_COUNTRY - Driver’s License →
DRLIC+DRIVERS_LICENSE_STATE LEI→LEI_NUMBERDUNS→DUNS_NUMBERNPI→NPI_NUMBER
-
Tax-related identifier
VAT,TIN,INN,EIN/FEIN, other tax codes- Map to
TAX_ID+TAX_ID_TYPE+TAX_ID_COUNTRY
-
Country-issued national identifier
- Unique per person/org within a country (e.g.,
CEDULA,SIREN,OGRN) - Map to
NATIONAL_ID+NATIONAL_ID_TYPE+NATIONAL_ID_COUNTRY
- Unique per person/org within a country (e.g.,
-
Unknown code? Research first
- Look up the token; confirm whether it is tax, national, or organization-issued (e.g., LEI).
- Maintain and consult a local crosswalk. Add aliases and verified findings to keep decisions consistent.
-
Everything else (last resort)
- Only if it is truly an identifier and not covered above:
OTHER_ID+OTHER_ID_TYPE[+OTHER_ID_COUNTRYwhen relevant]. - Do not default to
OTHER_IDwithout research (see “dumping-ground” warning below).
- Only if it is truly an identifier and not covered above:
Required context
- Always include issuer to scope uniqueness (e.g.,
PASSPORT_COUNTRY,DRIVERS_LICENSE_STATE,TAX_ID_COUNTRY). See “Identifiers → Principles” for uniqueness and issuer guidance.
Beware “dumping‑ground” identifier tables
- Some sources use code-driven “identifier” tables for anything lacking a dedicated field. You may encounter document dates (e.g., birth-certificate dates), risk categories/statuses, or free-text notes. Do not map these as identifiers (including
OTHER_ID). Route to a registered feature when appropriate; otherwise use payload attributes or omit when no meaningful, spec-compliant placement exists.
Common identifier mappings reference
| Identifier | Countries | Feature | Type | Example/Notes |
|---|---|---|---|---|
OGRN |
RU | NATIONAL_ID |
OGRN |
RU business registration |
INN |
RU | TAX_ID |
INN |
Russian tax number |
LEI |
International | LEI_NUMBER |
— | Legal Entity Identifier |
VAT |
EU/Global | TAX_ID |
VAT |
Value Added Tax ID |
CEDULA |
LATAM | NATIONAL_ID |
CEDULA |
National ID card |
SIREN |
FR | NATIONAL_ID |
SIREN |
FR business identifier |
TIN |
US/Global | TAX_ID |
TIN |
Taxpayer ID |
IMO |
International | OTHER_ID |
IMO |
Vessel identifier (no specific feature) |
| Passport | Any | PASSPORT |
— | Travel document |
SSN |
US | SSN |
— | US Social Security Number |
Mapping group associations (small groups only)
Purpose
- Use Group Associations only when the group is small and specific, materially narrowing the population.
- Intended for sparse data scenarios — when a person/organization is known primarily by a small group affiliation.
Use when the group is small/specific
- Examples:
OWNER_EXECof a company;BOARD_MEMBERof “ACME Corp”;CHAPTER_OFFICERSfor “Local Chapter 42”;PROJECT_TEAM“AML 2024”;ALUMNI_COHORT“CS 2008”. - Provide both a precise type and a specific group/organization name.
Do not use for large/generic populations
- Not acceptable: political parties (e.g.,
REPUBLICAN,DEMOCRAT), religions, national populations, country/state “residents”, mega social networks, extremely large unions or programs. - Do not encode broad categories like “EMPLOYEE” as a group association unless the subgroup is small and well‑bounded.
Examples
- Good:
GROUP_ASSOCIATION_TYPE=OWNER_EXEC;GROUP_ASSOCIATION_ORG_NAME=“ACME Corp” - Bad:
GROUP_ASSOCIATION_TYPE=POLITICAL_PARTY;GROUP_ASSOCIATION_ORG_NAME=“Democratic Party” - Bad:
GROUP_ASSOCIATION_TYPE=RESIDENTS;GROUP_ASSOCIATION_ORG_NAME=“United States”
Notes
- Group Associations are optional and have limited utility; prefer them only when they add discriminative power in sparse contexts.
Disclosed relationship mapping guidance
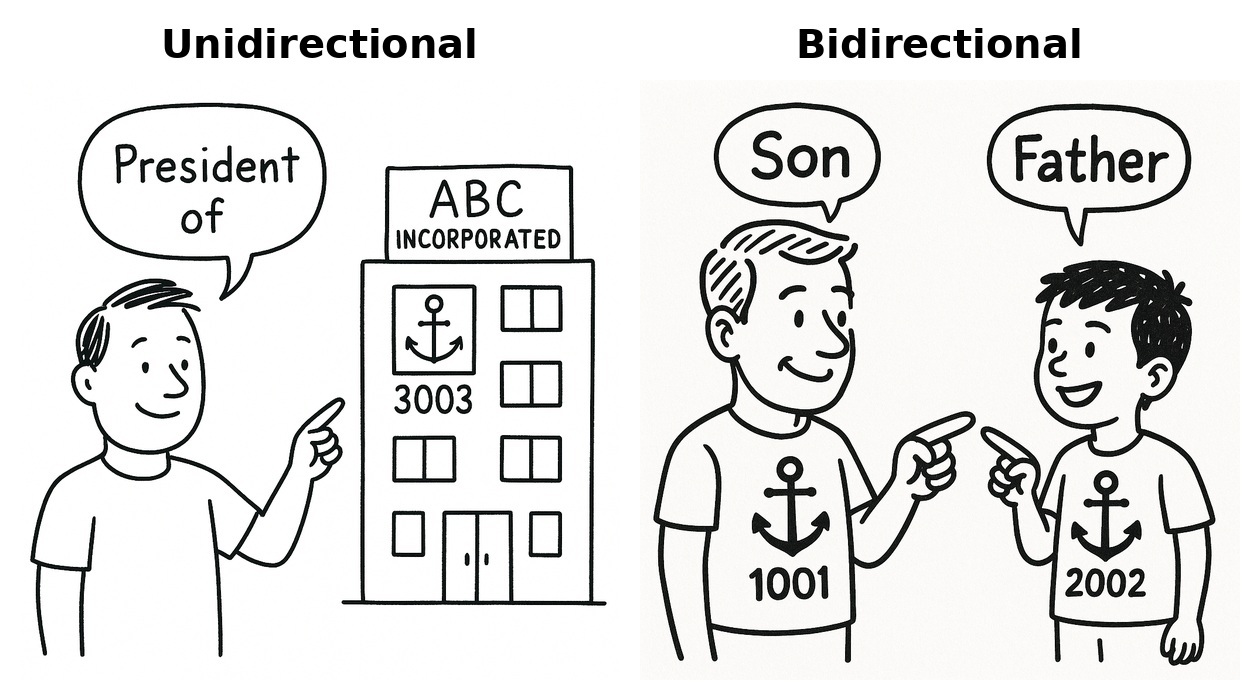
What it is
- Disclosed relationships connect source records (masters), not features.
- Common pairs and examples:
- Person ↔ Person: familial (e.g.,
SPOUSE_OF,SON_OF,FATHER_OF) - Person ↔ Organization: employment/ownership (e.g.,
EMPLOYED_BY,PRINCIPAL_OF,OWNER_OF) - Organization ↔ Organization: corporate hierarchy (e.g.,
BRANCH_OF,DIRECT_PARENT,ULTIMATE_PARENT)
- Person ↔ Person: familial (e.g.,
- Extensible: if you add new
RECORD_TYPEs (e.g.,VEHICLE,VESSEL), apply the same pattern (e.g.,OWNS_VESSEL,OPERATES_VEHICLE).
Direction and roles (how to assign anchor vs pointer)
- Single rule: the record doing the pointing holds
REL_POINTER_*; the record being pointed to holdsREL_ANCHOR_*. - Role-driven direction examples:
EMPLOYED_BY: Person → Organization (person hasREL_POINTER; organization hasREL_ANCHOR)BRANCH_OF: Branch org → Parent org (branch hasREL_POINTER; parent hasREL_ANCHOR)PRINCIPAL_OF: Person → Organization (person hasREL_POINTER; organization hasREL_ANCHOR)OWNER_OF: Person → Organization (person hasREL_POINTER; organization hasREL_ANCHOR)DIRECT_PARENT: Parent org → Child org (parent hasREL_POINTER; child hasREL_ANCHOR)ULTIMATE_PARENT: Top-level parent → Subsidiary (top-level hasREL_POINTER; subsidiary hasREL_ANCHOR)SPOUSE_OF: Often symmetric; emitting a single direction is acceptable if that’s what your source provides.SON_OF/FATHER_OF(directional verbs): Follow the verb —SON_OFmeans child → parent;FATHER_OFmeans parent → child.
Anchors: avoid second passes
- Place at most one
REL_ANCHORon any record that could be a target of relationships. - It’s safe and recommended to add
REL_ANCHORproactively (even if pointers aren’t known yet) so no second pass is required.
Model (anchor ↔ pointer)
- Anchor (target): add one
REL_ANCHORfeature object; never more than one per record. - Pointer (source): for each disclosed relationship leaving this record, add one
REL_POINTERfeature object with a role. - Do not mix
REL_ANCHOR_*andREL_POINTER_*keys in the same feature object.
Required fields
- Anchor:
REL_ANCHOR_DOMAIN,REL_ANCHOR_KEY(uniquely identifies the target record). - Pointer:
REL_POINTER_DOMAIN,REL_POINTER_KEY,REL_POINTER_ROLE(e.g.,SPOUSE_OF,SON_OF,FATHER_OF,EMPLOYED_BY,PRINCIPAL_OF,OWNER_OF,BRANCH_OF,DIRECT_PARENT,ULTIMATE_PARENT; standardize roles for filtering and display).
Map from common source shapes
- Link/bridge table: each link row → one
REL_POINTERon the source record; ensure the target record has oneREL_ANCHOR. - Foreign key on a master: the record with the FK gets a
REL_POINTER; the referenced record gets aREL_ANCHOR. - JSON/XML references: treat object references as links; emit
REL_POINTERon the referencing record andREL_ANCHORon the referenced record.
Domain and key
- Prefer
REL_*_DOMAIN = DATA_SOURCEandREL_*_KEY = RECORD_IDof the target record (or a stable link‑registry domain/key if you use one). - Keys must be unique within the domain; keep formats stable and deterministic.
Cardinality and integrity
- One anchor per record (max). Zero or more pointers per record.
- One relationship → one
REL_POINTERobject (multiple relationships → multiple objects). - Validate that every
REL_POINTERobject matches aREL_ANCHORobject on another record.
Examples
- EMPLOYED_BY (Person → Organization)
{
"DATA_SOURCE": "CUSTOMERS",
"RECORD_ID": "P1001",
"FEATURES": [
{
"REL_POINTER_DOMAIN": "CUSTOMERS",
"REL_POINTER_KEY": "ORG1001",
"REL_POINTER_ROLE": "EMPLOYED_BY"
}
]
}
{
"DATA_SOURCE": "CUSTOMERS",
"RECORD_ID": "ORG1001",
"FEATURES": [
{ "REL_ANCHOR_DOMAIN": "CUSTOMERS", "REL_ANCHOR_KEY": "ORG1001" }
]
}
- BRANCH_OF (Branch Org → Parent Org)
{
"DATA_SOURCE": "CUSTOMERS",
"RECORD_ID": "ORG2001",
"FEATURES": [
{
"REL_POINTER_DOMAIN": "CUSTOMERS",
"REL_POINTER_KEY": "ORG1001",
"REL_POINTER_ROLE": "BRANCH_OF"
}
]
}
{
"DATA_SOURCE": "CUSTOMERS",
"RECORD_ID": "ORG1001",
"FEATURES": [
{ "REL_ANCHOR_DOMAIN": "CUSTOMERS", "REL_ANCHOR_KEY": "ORG1001" }
]
}
- SON_OF / FATHER_OF (reciprocal pointers when provided)
{
"DATA_SOURCE": "CUSTOMERS",
"RECORD_ID": "PER1001",
"FEATURES": [
{ "REL_ANCHOR_DOMAIN": "CUSTOMERS", "REL_ANCHOR_KEY": "PER1001" },
{
"REL_POINTER_DOMAIN": "CUSTOMERS",
"REL_POINTER_KEY": "PER1002",
"REL_POINTER_ROLE": "SON_OF"
}
]
}
{
"DATA_SOURCE": "CUSTOMERS",
"RECORD_ID": "PER1002",
"FEATURES": [
{ "REL_ANCHOR_DOMAIN": "CUSTOMERS", "REL_ANCHOR_KEY": "PER1002" },
{
"REL_POINTER_DOMAIN": "CUSTOMERS",
"REL_POINTER_KEY": "PER1001",
"REL_POINTER_ROLE": "FATHER_OF"
}
]
}
Note: Each target record should also carry a single REL_ANCHOR (see pattern above).
See also
- Full field definitions and examples: Feature:
REL_ANCHORand Feature:REL_POINTERlater in this spec.
Additional configuration
Senzing comes pre-configured with all the features, attributes, and settings you will likely need to begin resolving persons and organizations immediately. The only configuration that really needs to be added is what you named your data sources.
How to add a data source
In your Senzing project’s bin directory is an application called sz_configtool. Adding a new data source is as simple as registering the code you want to use for it.
sz_configtool
Welcome to the Senzing configuration tool! Type help or ? to list commands
(sz_configtool) addDataSource CUSTOMERS
Data source successfully added!
(sz_configtool) save
Are you certain you wish to proceed and save changes? (y/n) y
Configuration changes saved!